CannaDB: A Cannabis Strain Library Built on atproto
I built CannaDB — a social cannabis strain database, breeder directory, and grow journal where every strain, review, and grow log is a record stored in your own PDS on the AT Protocol. It's live at cannadb.org and looking for testers.
I have a habit of building cannabis software. First it was Isley, a self-hosted grow journal, and then Growcast to stream the tent. The thing those two never solved was the question every grower eventually asks: what even is this plant, and who else has grown it? Strain data on the open web is a mess of SEO farms, dead seed-bank pages, and contradictory lineage. So I built a database for it — and because I can't help myself, I built it on the AT Protocol.
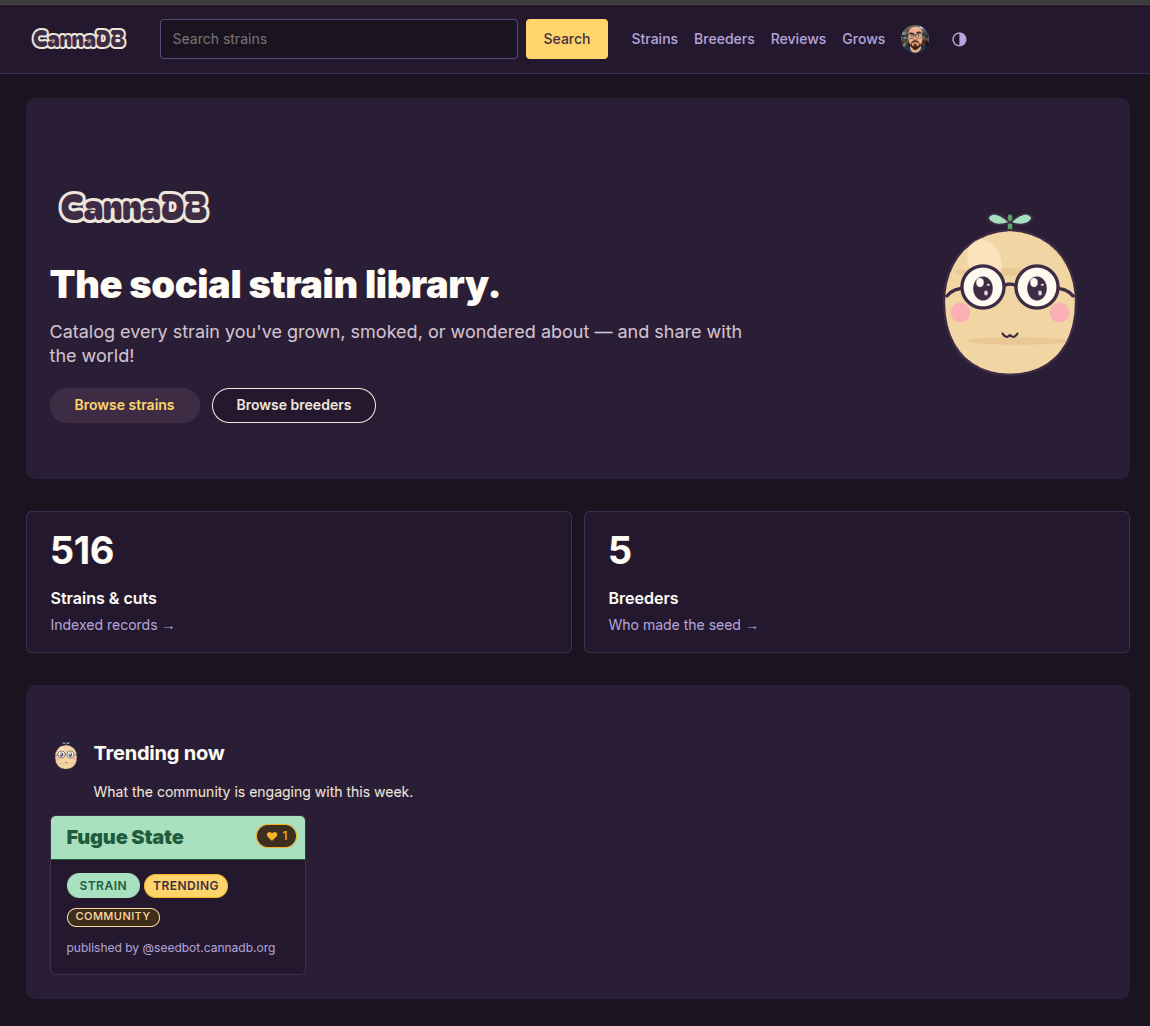
Meet CannaDB, a social strain library where every strain, edit, review, breeder, like, and grow journal is a record that lives in your data, not mine. It's live right now at cannadb.org.
A strain library, but the data is yours
Here's the part that makes CannaDB different from every other strain database. When you add a strain, write a review, or log a grow, that record isn't saved to a database I own. It's written to your PDS — your personal data server on atproto, the same open network that powers Bluesky. You sign in with your existing Bluesky handle (yourname.bsky.social works fine — no new account, no password for me to lose), and everything you create is signed by you and stored in your repo.
CannaDB itself is what atproto calls an AppView: an indexer and a presentation layer. It subscribes to the network firehose, watches for org.cannadb.* records as they're published anywhere on atproto, indexes them, and renders the site you're looking at. The app is a window onto public data — it doesn't own anything. If CannaDB disappeared tomorrow, your strain entries and grow logs would survive in your repo, ready for the next appview to come along and index them.
💡 The strain you catalog today outlives the website you catalog it on. That's the whole pitch for building on atproto.
What's in it today
The core of CannaDB is the strain catalog. Entries come in two flavors: a strain (a broad genetic identity, like "Blue Dream") and a cut (a specific phenotype, clone, or keeper pheno of a strain). Each entry can carry the things growers actually argue about — breeder, lineage and parents, autoflower vs. photoperiod, an indica/sativa lean on a 0–100 scale, THC and CBD ranges, flowering time, yield, height, difficulty, flavors, terpenes, and effects.
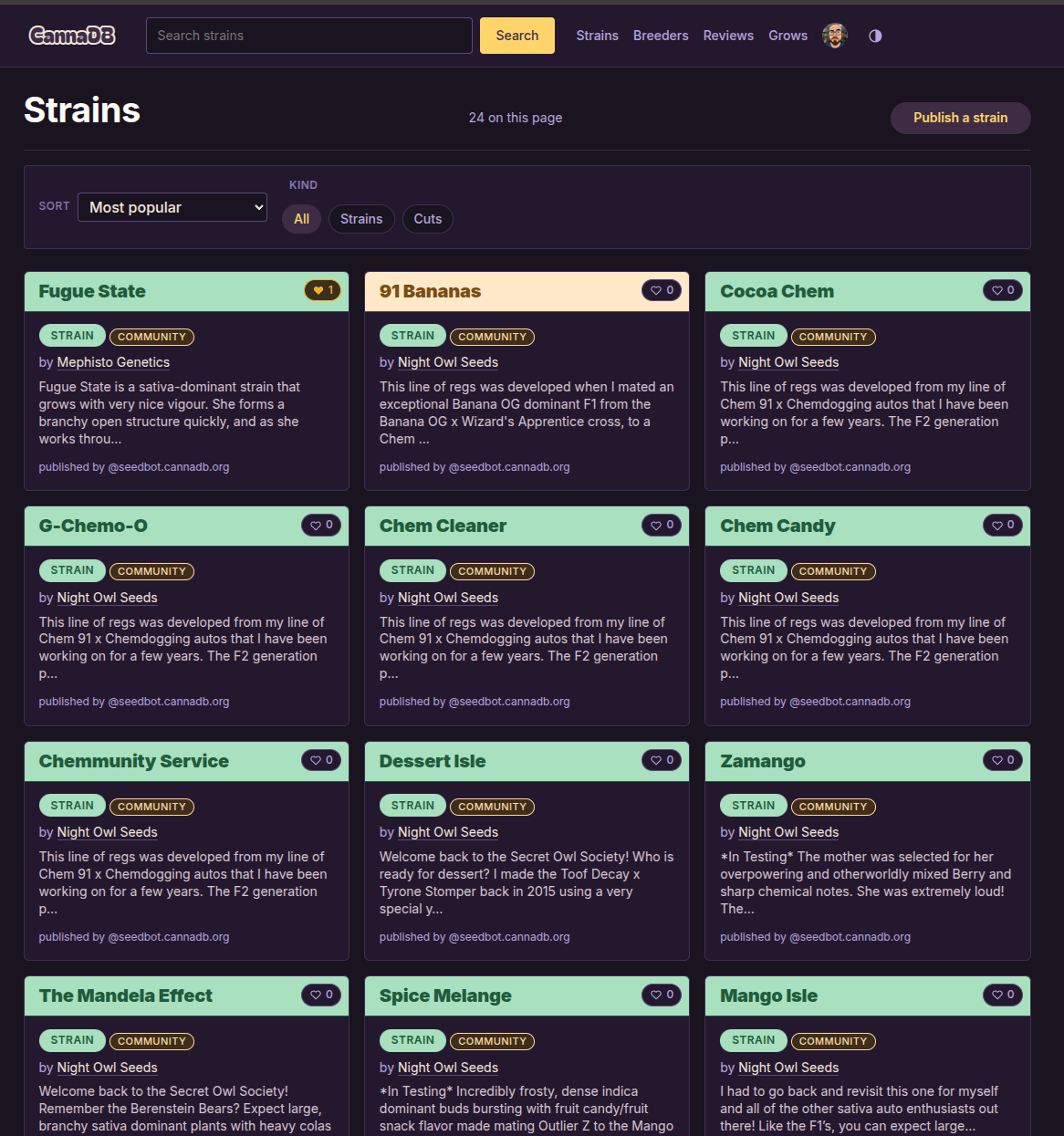
Strains link to each other through lineage, so you can walk a genealogy — this cut is a phenotype of that strain, which crossed these two parents. Breeders get their own records too, so a seed company can claim its identity and you can browse everything attributed to them.
Living records, not locked records
A strain page is more than a static entry. Because the data is open, records can be collaborative — a strain becomes a living record that the community can suggest edits to, with full history. Anyone can propose a correction; the edit trail is public. You can also leave a review with multi-axis ratings (overall, potency, yield, flavor, bag appeal, ease of grow), and like the strains you care about, which is what feeds the "trending now" panel on the homepage.
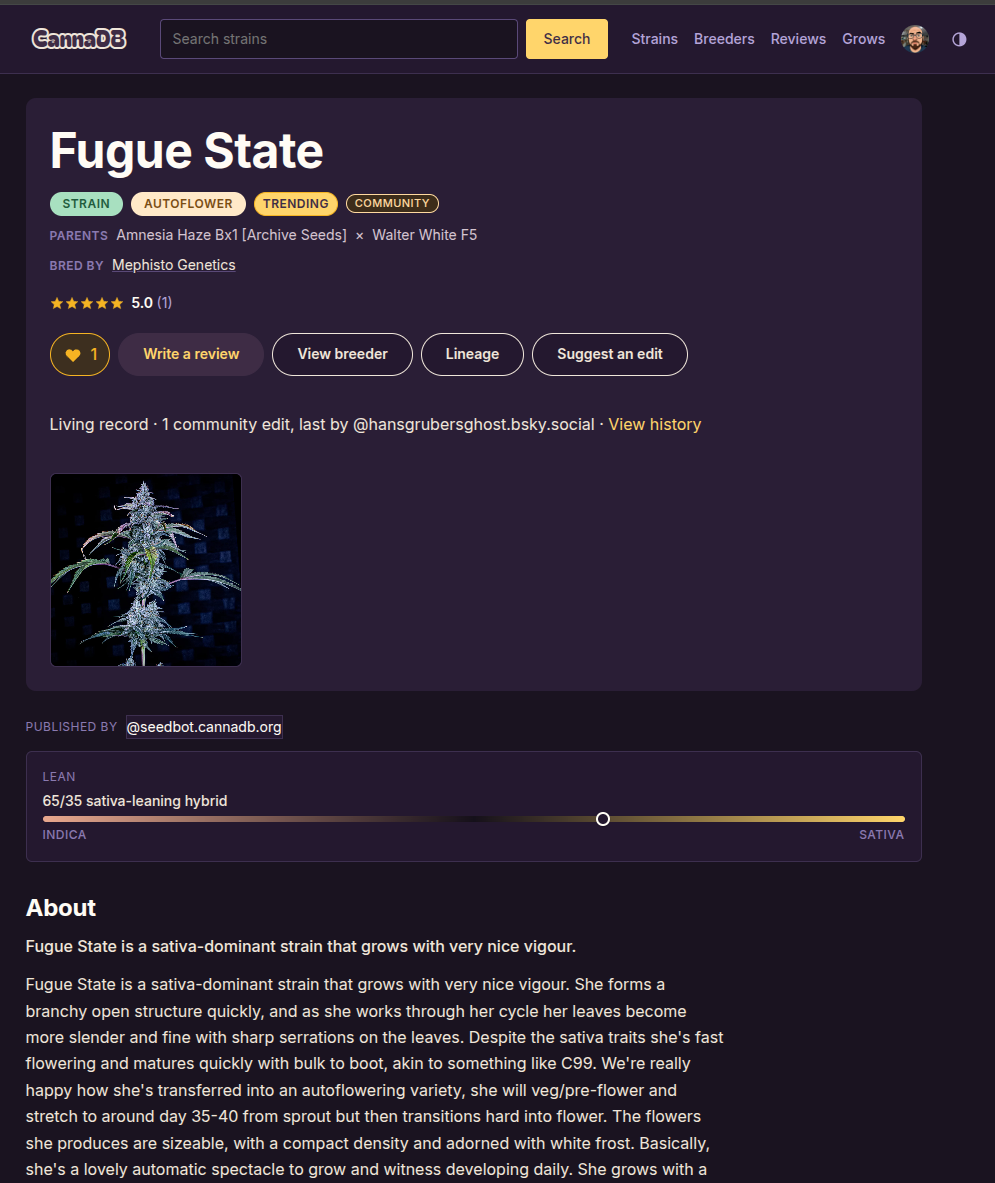
The newest piece: grow journalling
The feature I just shipped is a grow journal. You can start a grow, add the plants in it (each linked to a strain in the catalog), log dated entries with stages and measurements, attach photos, and track each plant from seedling through harvest with wet/dry weights and flowering days. It's a full grow record — and like everything else, it lives in your PDS.
If you read the Isley post, you know I'm a fan of self-hosting your grow data — and that's still the most powerful option if you want sensor automation and total control. But not everyone wants to run a container, and not everyone wants to hand their grow diary to GrowDiaries. CannaDB's grow journal is the in-between: a simple, no-setup place to document a run, where the data is still yours in a way a hosted platform can never offer. Self-host Isley if you want the full rig; use CannaDB if you just want to write it down and keep it.
Under the hood
For the atproto-curious: CannaDB is a single Go binary serving two surfaces. A read API exposes org.cannadb.* XRPC methods (getStrain, searchStrains, getLineage, and friends), and a server-rendered web UI serves the site, including OAuth-gated authoring forms that publish to your PDS via DPoP-signed com.atproto.repo.putRecord. Ingest is a Jetstream consumer that filters the firehose for CannaDB collections and indexes them into Postgres.
The record types — strain, cut, breeder, review, like, plus the grow set (grow, plant, grow entry, grow photo) — are defined as atproto lexicons, and the lexicon JSON is published at stable, byte-identical URLs that any other client or validator can fetch:
https://cannadb.org/lexicons/org.cannadb.strain.json
https://cannadb.org/lexicons/org.cannadb.breeder.json
https://cannadb.org/lexicons/org.cannadb.review.json
...The lexicons are CC0 — public domain — on purpose. The whole point of a shared schema is that someone else could build a competing, better CannaDB tomorrow and read the exact same records. The application code currently lives on my internal GitLab; I'll have more to say about opening it up as the project firms up.
Come break it
CannaDB is live and I want testers. Head to cannadb.org, sign in with your Bluesky handle, and add a strain you've grown, leave a review, or start logging a grow. Suggest an edit on a record that's wrong. Like the gear you love so it trends. Everything you create is yours and stays yours — I'm just the index.
I'm actively adding features, so if something's missing or broken, that's useful signal. Plant something.